relu函数有上界吗(relu函数是线性的吗)
 小楼夜听雨
小楼夜听雨- 体育
- 2023-03-13 18:46:01
- -
原来ReLU这么好用!一文带你深度了解ReLU激活函数!
在神经网络中,激活函数负责将来自节点的加权输入转换为该输入的节点或输出的激活。ReLU 是一个分段线性函数,如果输入为正,它将直接输出,否则,它将输出为零。它已经成为许多类型神经网络的默认激活函数,因为使用它的模型更容易训练,并且通常能够获得更好的性能。在本文中,我们来详细介绍一下ReLU,主要分成以下几个部分:
1、Sigmoid 和 Tanh 激活函数的局限性
2、ReLU(Rectified Linear Activation Function)
3、如何实现ReLU
4、ReLU的优点
5、使用ReLU的技巧
一个神经网络由层节点组成,并学习将输入的样本映射到输出。对于给定的节点,将输入乘以节点中的权重,并将其相加。此值称为节点的summed activation。然后,经过求和的激活通过一个激活函数转换并定义特定的输出或节点的“activation”。
最简单的激活函数被称为线性激活,其中根本没有应用任何转换。 一个仅由线性激活函数组成的网络很容易训练,但不能学习复杂的映射函数。线性激活函数仍然用于预测一个数量的网络的输出层(例如回归问题)。
非线性激活函数是更好的,因为它们允许节点在数据中学习更复杂的结构 。两个广泛使用的非线性激活函数是 sigmoid 函数和 双曲正切 激活函数。
Sigmoid 激活函数 ,也被称为 Logistic函数神经网络,传统上是一个非常受欢迎的神经网络激活函数。函数的输入被转换成介于0.0和1.0之间的值。大于1.0的输入被转换为值1.0,同样,小于0.0的值被折断为0.0。所有可能的输入函数的形状都是从0到0.5到1.0的 s 形。在很长一段时间里,直到20世纪90年代早期,这是神经网络的默认激活方式。
双曲正切函数 ,简称 tanh,是一个形状类似的非线性激活函数,输出值介于-1.0和1.0之间。在20世纪90年代后期和21世纪初期,由于使用 tanh 函数的模型更容易训练,而且往往具有更好的预测性能,因此 tanh 函数比 Sigmoid激活函数更受青睐。
Sigmoid和 tanh 函数的一个普遍问题是它们值域饱和了 。这意味着,大值突然变为1.0,小值突然变为 -1或0。此外,函数只对其输入中间点周围的变化非常敏感。
无论作为输入的节点所提供的求和激活是否包含有用信息,函数的灵敏度和饱和度都是有限的。一旦达到饱和状态,学习算法就需要不断调整权值以提高模型的性能。
最后,随着硬件能力的提高,通过 gpu 的非常深的神经网络使用Sigmoid 和 tanh 激活函数不容易训练。在大型网络深层使用这些非线性激活函数不能接收有用的梯度信息。错误通过网络传播回来,并用于更新权重。每增加一层,错误数量就会大大减少。这就是所谓的 消失梯度 问题,它能有效地阻止深层(多层)网络的学习。
虽然非线性激活函数的使用允许神经网络学习复杂的映射函数,但它们有效地阻止了学习算法与深度网络的工作。在2000年代后期和2010年代初期,通过使用诸如波尔兹曼机器和分层训练或无监督的预训练等替代网络类型,这才找到了解决办法。
为了训练深层神经网络, 需要一个激活函数神经网络,它看起来和行为都像一个线性函数,但实际上是一个非线性函数,允许学习数据中的复杂关系 。该函数还必须提供更灵敏的激活和输入,避免饱和。
因此,ReLU出现了, 采用 ReLU 可以是深度学习革命中为数不多的里程碑之一 。ReLU激活函数是一个简单的计算,如果输入大于0,直接返回作为输入提供的值;如果输入是0或更小,返回值0。
我们可以用一个简单的 if-statement 来描述这个问题,如下所示:
对于大于零的值,这个函数是线性的,这意味着当使用反向传播训练神经网络时,它具有很多线性激活函数的理想特性。然而,它是一个非线性函数,因为负值总是作为零输出。由于矫正函数在输入域的一半是线性的,另一半是非线性的,所以它被称为 分段线性函数(piecewise linear function ) 。
我们可以很容易地在 Python 中实现ReLU激活函数。
我们希望任何正值都能不变地返回,而0.0或负值的输入值将作为0.0返回。
下面是一些修正的线性激活函数的输入和输出的例子:
输出如下:
我们可以通过绘制一系列的输入和计算出的输出,得到函数的输入和输出之间的关系。下面的示例生成一系列从 -10到10的整数,并计算每个输入的校正线性激活,然后绘制结果。
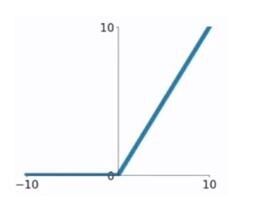
运行这个例子会创建一个图,显示所有负值和零输入都突变为0.0,而正输出则返回原样:
ReLU函数的导数是斜率。负值的斜率为0.0,正值的斜率为1.0。
传统上,神经网络领域已经不能是任何不完全可微的激活函数,而ReLU是一个分段函数。从技术上讲,当输入为0.0时,我们不能计算ReLU的导数,但是,我们可以假设它为0。
tanh 和 sigmoid 激活函数需要使用指数计算, 而ReLU只需要max(),因此他 计算上更简单,计算成本也更低 。
ReLU的一个重要好处是,它能够输出一个真正的零值 。这与 tanh 和 sigmoid 激活函数不同,后者学习近似于零输出,例如一个非常接近于零的值,但不是真正的零值。这意味着负输入可以输出真零值,允许神经网络中的隐层激活包含一个或多个真零值。这就是所谓的稀疏表示,是一个理想的性质,在表示学习,因为它可以加速学习和简化模型。
ReLU看起来更像一个线性函数,一般来说,当神经网络的行为是线性或接近线性时,它更容易优化 。
这个特性的关键在于,使用这个激活函数进行训练的网络几乎完全避免了梯度消失的问题,因为梯度仍然与节点激活成正比。
ReLU的出现使得利用硬件的提升和使用反向传播成功训练具有非线性激活函数的深层多层网络成为可能 。
很长一段时间,默认的激活方式是Sigmoid激活函数。后来,Tanh成了激活函数。 对于现代的深度学习神经网络,默认的激活函数是ReLU激活函数 。
ReLU 可以用于大多数类型的神经网络, 它通常作为多层感知机神经网络和卷积神经网络的激活函数 ,并且也得到了许多论文的证实。传统上,LSTMs 使用 tanh 激活函数来激活cell状态,使用 Sigmoid激活函数作为node输出。 而ReLU通常不适合RNN类型网络的使用。
偏置是节点上具有固定值的输入,这种偏置会影响激活函数的偏移,传统的做法是将偏置输入值设置为1.0。当在网络中使用 ReLU 时, 可以将偏差设置为一个小值,例如0.1 。
在训练神经网络之前,网络的权值必须初始化为小的随机值。当在网络中使用 ReLU 并将权重初始化为以零为中心的小型随机值时,默认情况下,网络中一半的单元将输出零值。有许多启发式方法来初始化神经网络的权值,但是没有最佳权值初始化方案。 何恺明的文章指出Xavier 初始化和其他方案不适合于 ReLU ,对 Xavier 初始化进行一个小的修改,使其适合于 ReLU,提出He Weight Initialization,这个方法更适用于ReLU 。
在使用神经网络之前对输入数据进行缩放是一个很好的做法。这可能涉及标准化变量,使其具有零均值和单位方差,或者将每个值归一化为0到1。如果不对许多问题进行数据缩放,神经网络的权重可能会增大,从而使网络不稳定并增加泛化误差。 无论是否在网络中使用 ReLU,这种缩放输入的良好实践都适用。
ReLU 的输出在正域上是无界的。这意味着在某些情况下,输出可以继续增长。因此,使用某种形式的权重正则化可能是一个比较好的方法,比如 l1或 l2向量范数。 这对于提高模型的稀疏表示(例如使用 l 1正则化)和降低泛化误差都是一个很好的方法 。
.
数据挖掘算法基础 - 各种辅助函数及应用
符号函数是一个很神奇的东西,坐拥简单、求导方便等优点,非常适合用于机器学习的目标函数和激活函数中。
是一个符号函数,可以理解为tanh函数的特殊化,满足以下条件:
当x0,sign(x)=1;
当x=0,sign(x)=0;
当x0, sign(x)=-1;
函数图像是:
tanh函数是双曲正切函数,是高中数学中的一个基础函数,基本形式如下:
这个函数,求导也比较好求,其实我们可以发现带e的求导都比较简单,tanh函数求导以后的形式为:
tanh函数的图像是下边这样的:
sigmoid是最常用的激活函数,或者说最常用的分类函数的目标函数,sigmoid的基本形式为:
它求导也有优良的性能,
sigmoid的导数值在0-1之间如果用于激活函数,容易造成梯度消失。
sigmoid的进阶版是softmax用于多分类问题,基本形式如下:
可以看做是softmax的一种近似,函数形式为:
函数图像为:
传统的Relu函数是0,x分段函数,基本形式是:
函数图像为:
Swish函数具备有下界无上界,平滑、非单调的特性。在深层模型上效果优于Relu。
函数图像为:
一般的深度神经网络隐藏层节点的输出都要经过sigmoid激活一下,但是maxout的思想是,取最大而非经过函数计算。
实验表明,maxout和dropout结合有奇效。
[img]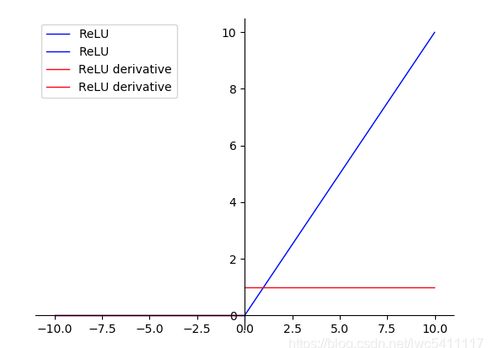
激活函数总结
什么是激活函数
激活函数在神经网络当中的作用**是赋予神经网络更多的非线性因素。如果不用激活函数,网络的输出是输入的线性组合,这种情况与最原始的感知机相当,网络的逼近能力相当有限。如果能够引入恰当的非线性函数作为激活函数,这样神经网络逼近能力就能够更加强大。
激活函数(Activation functions)对于神经网络模型学习与理解复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。
如果网络中不使用激活函数,网络每一层的输出都是上层输入的线性组合,无论神经网络有多少层,输出都是输入的线性组合。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,此时神经网络就可以应用到各类非线性场景当中了。
常见的激活函数如sigmoid、tanh、relu等,它们的输入输出映射均为非线性,这样才可以给网络赋予非线性逼近能力。
下图为Relu激活函数,由于在0点存在非线性转折,该函数为非线性激活函数:
常用的激活函数
1、Sigmoid
Sigmoid函数是一个在生物学中常见的S型函数,它能够把输入的连续实值变换为0和1之间的输出,如果输入是特别小的负数,则输出为0,如果输入是特别大的正数,则输出为1。即将输入量映射到0到1之间。
Sigmoid可以作为非线性激活函数赋予网络非线性区分能力,也可以用来做二分类。其计算公式为:
曲线过渡平滑,处处可导;
缺点:
幂函数运算较慢,激活函数计算量大;
求取反向梯度时,Sigmoid的梯度在饱和区域非常平缓,很容易造称梯度消失的问题,减缓收敛速度。
2、Tanh
Tanh是一个奇函数,它能够把输入的连续实值变换为-1和1之间的输出,如果输入是特别小的负数,则输出为-1,如果输入是特别大的正数,则输出为1;解决了Sigmoid函数的不是0均值的问题。
曲线过渡平滑,处处可导;
具有良好的对称性,网络是0均值的。
缺点:
与Sigmoid类似,幂函数运算较慢,激活函数计算量大;
与Sigmoid类似,求取反向梯度时,Tanh的梯度在饱和区域非常平缓,很容易造称梯度消失的问题,减缓收敛速度。
3、ReLU
线性整流函数(Rectified Linear Unit, ReLU),是一种深度神经网络中常用的激活函数,整个函数可以分为两部分,在小于0的部分,激活函数的输出为0;在大于0的部分,激活函数的输出为输入。计算公式为:
收敛速度快,不存在饱和区间,在大于0的部分梯度固定为1,有效解决了Sigmoid中存在的梯度消失的问题;
计算速度快,ReLU只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的指数运算,具有类生物性质。
缺点:
它在训练时可能会“死掉”。如果一个非常大的梯度经过一个ReLU神经元,更新过参数之后,这个神经元的的值都小于0,此时ReLU再也不会对任何数据有激活现象了。如果这种情况发生,那么从此所有流过这个神经元的梯度将都变成 0。合理设置学习率,会降低这种情况的发生概率。
先进的激活函数
1、LeakyReLU
LeakyReLU具有ReLU的优点;
解决了ReLU函数存在的问题,防止死亡神经元的出现。
缺点:
α参数人工选择,具体的的值仍然需要讨论。
2、PReLU
PReLU具有LeakyReLU的优点;
解决了LeakyReLU函数存在的问题,让神经网络自适应选择参数。
3、ReLU6
ReLU6就是普通的ReLU但是限制最大输出为6,用在MobilenetV1网络当中。目的是为了适应float16/int8 的低精度需要
优点:
ReLU6具有ReLU函数的优点;
该激活函数可以在移动端设备使用float16/int8低精度的时候也能良好工作。如果对 ReLU 的激活范围不加限制,激活值非常大,则低精度的float16/int8无法很好地精确描述如此大范围的数值,带来精度损失。
缺点:
与ReLU缺点类似。
4、Swish
Swish是Sigmoid和ReLU的改进版,类似于ReLU和Sigmoid的结合,β是个常数或可训练的参数。Swish 具备无上界有下界、平滑、非单调的特性。Swish 在深层模型上的效果优于 ReLU。
优点:
Swish具有一定ReLU函数的优点;
Swish具有一定Sigmoid函数的优点;
Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数。
缺点:
运算复杂,速度较慢。
5、Mish
Mish与Swish激活函数类似,Mish具备无上界有下界、平滑、非单调的特性。Mish在深层模型上的效果优于 ReLU。无上边界可以避免由于激活值过大而导致的函数饱和。
优点:
Mish具有一定ReLU函数的优点,收敛快速;
Mish具有一定Sigmoid函数的优点,函数平滑;
Mish函数可以看做是介于线性函数与ReLU函数之间的平滑函数。
缺点:
运算复杂,速度较慢。
5、Swish和Mish的梯度对比。
原文链接:
本文由作者笔名:小楼夜听雨 于 2023-03-13 18:46:01发表在本站,原创文章,禁止转载,文章内容仅供娱乐参考,不能盲信。
本文链接:https://www.e-8.com.cn/ty-117798.html
随机推荐

羽毛球哪种球属于违例,还有犯规球(羽毛球发球违例怎么判)
2022-12-21
周深唱过哪些歌(周深最震撼十首歌)
2022-12-20
达州职业技术学院单招报名可以填几个职业(达州招生网官网)
2022-12-24
胡歌当初那么喜欢刘诗诗,为何最后没能在一起(胡歌对刘诗诗的看法)
2023-01-12
夜幕下的哈尔滨主要讲了什么故事有什么主要情节么...(夜幕下的哈尔滨免费)
2023-01-10
《无主之城》结局中哪些角色领了盒饭(无主之城莫俪的结局)
2023-01-27
平安新人543具体内容(平安新人543内容4)
2023-03-28
我们要好好的电视剧免费(我们要好好的电视剧免费西瓜影音)
2023-05-06
热门文章

世乒赛女单决赛直播cctv5的简单介绍
2023-03-15
屋顶歌词周杰伦(屋顶歌词周杰伦男女分开)
2023-10-15
已知两段速度怎么求平均速度(已知两段平均速度求总平均速度)
2023-03-25
求老版央视三国演义电视剧全集下载(BT种子高清),谢谢!(旧版三国演义第84集)
2023-01-25
萱萱的资料(角头2潘帅老婆陈孝萱)
2023-02-26
《人类(2015)》免费在线观看完整版高清,求百度网盘资源(zozozoozoo与动物)
2023-01-03
吴尊汪东城为辰亦儒庆生,为何没有炎亚纶呢(汪东城生活现状)
2023-01-17
《弥留之国的爱丽丝》讲述了什么(弥留之城)
2023-01-14