sigmoid函数的输出值(sigmoid输出是概率吗)
 丿聚焦丶灬
丿聚焦丶灬- 旅游
- 2023-03-29 18:44:01
- -
简单介绍神经网络算法
直接简单介绍神经网络算法
神经元:它是神经网络的基本单元。神经元先获得输入,然后执行某些数学运算后,再产生一个输出。
神经元内输入 经历了3步数学运算,
先将两个输入乘以 权重 :
权重 指某一因素或指标相对于某一事物的重要程度,其不同于一般的比重,体现的不仅仅是某一因素或指标所占的百分比,强调的是因素或指标的相对重要程度
x1→x1 × w1
x2→x2 × w2
把两个结果相加,加上一个 偏置 :
(x1 × w1)+(x2 × w2)+ b
最后将它们经过 激活函数 处理得到输出:
y = f(x1 × w1 + x2 × w2 + b)
激活函数 的作用是将无限制的输入转换为可预测形式的输出。一种常用的激活函数是 sigmoid函数
sigmoid函数的输出 介于0和1,我们可以理解为它把 (−∞,+∞) 范围内的数压缩到 (0, 1)以内。正值越大输出越接近1,负向数值越大输出越接近0。
神经网络: 神经网络就是把一堆神经元连接在一起
隐藏层 是夹在输入输入层和输出层之间的部分,一个神经网络可以有多个隐藏层。
前馈 是指神经元的输入向前传递获得输出的过程
训练神经网络 ,其实这就是一个优化的过程,将损失最小化
损失 是判断训练神经网络的一个标准
可用 均方误差 定义损失
均方误差 是反映 估计量 与 被估计量 之间差异程度的一种度量。设t是根据子样确定的总体参数θ的一个估计量,(θ-t)2的 数学期望 ,称为估计量t的 均方误差 。它等于σ2+b2,其中σ2与b分别是t的 方差 与 偏倚 。
预测值 是由一系列网络权重和偏置计算出来的值
反向传播 是指向后计算偏导数的系统
正向传播算法 是由前往后进行的一个算法
sigmoid和softmax函数详解
参考: ;wfr=spiderfor=pc
在一个最近的一个项目中,发现自己对sigmoid函数和softmax函数的概念和用法比较模糊,特地做一下总结
假设一张图片丢进一个神经网络(例如resnet50),最后的输出为一个向量,如[-0.5, 1.2, -0.1, 2.4],分别对应四中不同的标签.
Sigmoid函数或Softmax函数可以将分类器的原始输出值映射为概率。那么什么时候用到sigmoid,什么时候用softmax呢?
下图显示了将前馈神经网络的原始输出值(蓝色)通过Sigmoid函数映射为概率(红色)的过程:
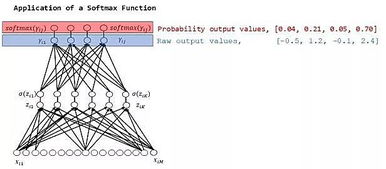
然后采用Softmax函数重复上述过程:
如图所示,Sigmoid函数和Softmax函数得出不同结果。
原因在于,Sigmoid函数会分别处理各个原始输出值,因此其结果相互独立,概率总和不一定为1,如图0.37 + 0.77 + 0.48 + 0.91 = 2.53。
相反,Softmax函数的输出值相互关联,其概率的总和始终为1,如图0.04 + 0.21 + 0.05 + 0.70 = 1.00。因此,在Softmax函数中,为增大某一类别的概率,其他类别的概率必须相应减少
Sigmoid函数如下所示(注意e):
在该公式中,σ表示Sigmoid函数,σ(zj)表示将Sigmoid函数应用于数字Zj。 “Zj”表示单个原始输出值,如-0.5。 j表示当前运算的输出值。如果有四个原始输出值,则j = 1,2,3或4。在前面的例子中,原始输出值为[-0.5,1.2,-0.1,2.4],则Z1 = -0.5,Z2 = 1.2,Z3 = -0.1,Z4 = 2.4。
所以,
Z2,Z3、Z4 的计算过程同上。
由于Sigmoid函数分别应用于每个原始输出值,因此可能出现的输出情况包括:所有类别概率都很低一种类别的概率很高但是其他类别的概率很低,多个或所有类别的概率都很高。
下图为Sigmoid函数曲线:
Sigmoid =多标签分类问题=多个正确答案=非独占输出(例如胸部X光检查、住院)
构建分类器,解决有多个正确答案的问题时,用Sigmoid函数分别处理各个原始输出值 。
Softmax函数的分母综合了原始输出值的所有因素,这意味着,Softmax函数得到的不同概率之间相互关联。
Softmax函数表述如下:
除分母外,为综合所有因素,将原始输出值中的e ^ thing相加,Softmax函数与Sigmoid函数差别不大。换言之,用Softmax函数计算单个原始输出值(例如Z1)时,不能只计算Z1,分母中的Z1,Z2,Z3和Z4也应加以计算,如下所示:
区分手写数字时,用Softmax函数处理原始输出值,如要增加某一示例被分为“8”的概率,就要降低该示例被分到其他数字(0,1,2,3,4,5,6,7和/或9)的概率。
Softmax =多类别分类问题=只有一个正确答案=互斥输出(例如手写数字,鸢尾花)
构建分类器,解决只有唯一正确答案的问题时,用Softmax函数处理各个原始输出值。
[img]
神经网络:损失函数详解
交叉熵代价函数(Cross-entropy cost function)是用来衡量人工神经网络(ANN)的预测值与实际值的一种方式。与二次代价函数相比,它能更有效地促进ANN的训练。在介绍交叉熵代价函数之前,本文先简要介绍二次代价函数,以及其存在的不足。
1. 二次代价函数的不足
ANN的设计目的之一是为了使机器可以像人一样学习知识。人在学习分析新事物时,当发现自己犯的错误越大时,改正的力度就越大。比如投篮:当运动员发现自己的投篮方向离正确方向越远,那么他调整的投篮角度就应该越大,篮球就更容易投进篮筐。同理, 我们希望:ANN在训练时,如果预测值与实际值的误差越大,那么在 反向传播训练 的过程中,各种参数调整的幅度就要更大,从而使训练更快收敛。 然而,如果使用二次代价函数训练ANN,看到的实际效果是,如果误差越大,参数调整的幅度可能更小,训练更缓慢。
以一个神经元的二类分类训练为例,进行两次实验(ANN常用的激活函数为sigmoid函数,该实验也采用该函数):输入一个相同的样本数据x=1.0(该样本对应的实际分类y=0);两次实验各自随机初始化参数,从而在各自的第一次前向传播后得到不同的输出值,形成不同的代价(误差):
实验1:第一次输出值为0.82
实验2:第一次输出值为0.98
在实验1中,随机初始化参数,使得第一次输出值为0.82(该样本对应的实际值为0);经过300次迭代训练后,输出值由0.82降到0.09,逼近实际值。而在实验2中,第一次输出值为0.98,同样经过300迭代训练,输出值只降到了0.20。
从两次实验的代价曲线中可以看出: 实验1的代价随着训练次数增加而快速降低,但实验2的代价在一开始下降得非常缓慢;直观上看,初始的误差越大,收敛得越缓慢 。
其实,误差大导致训练缓慢的原因在于使用了二次代价函数。二次代价函数的公式如下:
其中,C表示代价,x表示样本,y表示实际值,a表示输出值,n表示样本的总数。为简单起见,同样一个样本为例进行说明,此时二次代价函数为:
目前训练ANN最有效的 算法 是 反向传播算法 。简而言之,训练ANN就是通过反向传播代价,以减少代价为导向,调整参数。参数主要有:神经元之间的连接权重w,以及每个神经元本身的偏置b。调参的方式是采用梯度下降算法(Gradient
descent),沿着梯度方向调整参数大小。w和b的梯度推导如下:
其中,z表示神经元的输入,
表示激活函数。从以上公式可以看出,w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整得越快,训练收敛得就越快。而神经网络常用的激活函数为sigmoid函数,该函数的曲线如下所示:
如图所示, 实验2的初始输出值(0.98)对应的梯度明显小于实验1的输出值(0.82),因此实验2的参数梯度下降得比实验1慢。这就是初始的代价(误差)越大,导致训练越慢的原因。 与我们的期望不符,即:不能像人一样,错误越大,改正的幅度越大,从而学习得越快。
可能有人会说,那就选择一个梯度不变化或变化不明显的激活函数不就解决问题了吗?图样图森破,那样虽然简单粗暴地解决了这个问题,但可能会引起其他更多更麻烦的问题。而且,类似sigmoid这样的函数(比如tanh函数)有很多优点,非常适合用来做激活函数,具体请自行google之。
2. 交叉熵代价函数
换个思路,我们不换激活函数,而是换掉二次代价函数,改用交叉熵代价函数:
其中,x表示样本,n表示样本的总数。那么,重新计算参数w的梯度:
其中(具体证明见附录):
因此,w的梯度公式中原来的
被消掉了;另外,该梯度公式中的
表示输出值与实际值之间的误差。所以,当误差越大,梯度就越大,参数w调整得越快,训练速度也就越快。同理可得,b的梯度为:
实际情况证明,交叉熵代价函数带来的训练效果往往比二次代价函数要好。
3. 交叉熵代价函数是如何产生的?
以偏置b的梯度计算为例,推导出交叉熵代价函数:
在第1小节中,由二次代价函数推导出来的b的梯度公式为:
为了消掉该公式中的
,我们想找到一个代价函数使得:
即:
对两侧求积分,可得:
而这就是前面介绍的交叉熵代价函数。
附录:
sigmoid函数为:
可证:
更系统的回答:
在之前的内容中,我们用的损失函数都是平方差函数,即
C=12(a−y)2
其中y是我们期望的输出,a为神经元的实际输出(a=σ(Wx+b)。也就是说,当神经元的实际输出与我们的期望输出差距越大,代价就越高。想法非常的好,然而在实际应用中,我们知道参数的修正是与∂C∂W和∂C∂b成正比的,而根据
∂C∂W=(a−y)σ′(a)xT∂C∂b=(a−y)σ′(a)
我们发现其中都有σ′(a)这一项。因为sigmoid函数的性质,导致σ′(z)在z取大部分值时会造成饱和现象,从而使得参数的更新速度非常慢,甚至会造成离期望值越远,更新越慢的现象。那么怎么克服这个问题呢?我们想到了交叉熵函数。我们知道,熵的计算公式是
H(y)=−∑iyilog(yi)
而在实际操作中,我们并不知道y的分布,只能对y的分布做一个估计,也就是算得的a值, 这样我们就能够得到用a来表示y的交叉熵
H(y,a)=−∑iyilog(ai)
如果有多个样本,则整个样本的平均交叉熵为
H(y,a)=−1n∑n∑iyi,nlog(ai,n)
其中n表示样本编号,i表示类别编。 如果用于logistic分类,则上式可以简化成
H(y,a)=−1n∑nylog(a)+(1−y)log(1−a)
与平方损失函数相比,交叉熵函数有个非常好的特质,
H′=1n∑(an−yn)=1n∑(σ(zn)−yn)
可以看到其中没有了σ′这一项,这样一来也就不会受到饱和性的影响了。当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。这是一个很好的性质。
3.总结
当我们用sigmoid函数作为神经元的激活函数时,最好使用交叉熵代价函数来替代方差代价函数,以避免训练过程太慢。
不过,你也许会问,为什么是交叉熵函数?导数中不带σ′(z)项的函数有无数种,怎么就想到用交叉熵函数?这自然是有来头的,更深入的讨论就不写了,少年请自行了解。
另外,交叉熵函数的形式是−[ylna+(1−y)ln(1−a)]而不是
−[alny+(1−a)ln(1−y)],为什么?因为当期望输出的y=0时,lny没有意义;当期望y=1时,ln(1-y)没有意义。而因为a是sigmoid函数的实际输出,永远不会等于0或1,只会无限接近于0或者1,因此不存在这个问题。
4.还要说说:log-likelihood cost
对数似然函数也常用来作为softmax回归的代价函数,在上面的讨论中,我们最后一层(也就是输出)是通过sigmoid函数,因此采用了交叉熵代价函数。而 深度学习 中更普遍的做法是将softmax作为最后一层,此时常用的是代价函数是log-likelihood cost。
In fact, it’s useful to think of a softmax output layer with
log-likelihood cost as being quite similar to a sigmoid output layer
with cross-entropy cost。
其实这两者是一致的,logistic回归用的就是sigmoid函数,softmax回归是logistic回归的多类别推广。log-likelihood代价函数在二类别时就可以化简为交叉熵代价函数的形式。
补充一个困扰我很久的问题:
;mid=502840969idx=1sn=05b8d27dccf6efc3f85f47a74669e1c9#rd
总结:
softmax 损失函数,适合单标签多分类问题
欧式损失函数(就是均方误差),适合实数值回归问题
sigmod 交叉熵,适合多标签分类问题,这里上面说是主要用在二分类,暂时理解为多标签二分类问题。
contrastive loss,适合深度测度学习,就是siamese网络的相似度学习。
神经网络中的各种损失函数介绍
不同的损失函数可用于不同的目标。在这篇文章中,我将带你通过一些示例介绍一些非常常用的损失函数。这篇文章提到的一些参数细节都属于tensorflow或者keras的实现细节。
损失函数的简要介绍
损失函数有助于优化神经网络的参数。我们的目标是通过优化神经网络的参数(权重)来最大程度地减少神经网络的损失。通过神经网络将目标(实际)值与预测值进行匹配,再经过损失函数就可以计算出损失。然后,我们使用梯度下降法来优化网络权重,以使损失最小化。这就是我们训练神经网络的方式。
均方误差
当你执行回归任务时,可以选择该损失函数。顾名思义,这种损失是通过计算实际(目标)值和预测值之间的平方差的平均值来计算的。
例如,你有一个神经网络,通过该网络可以获取一些与房屋有关的数据并预测其价格。在这种情况下,你可以使用MSE(均方误差)损失。基本上,在输出为实数的情况下,应使用此损失函数。
二元交叉熵
当你执行二元分类任务时,可以选择该损失函数。如果你使用BCE(二元交叉熵)损失函数,则只需一个输出节点即可将数据分为两类。输出值应通过sigmoid激活函数,以便输出在(0-1)范围内。
例如,你有一个神经网络,该网络获取与大气有关的数据并预测是否会下雨。如果输出大于0.5,则网络将其分类为会下雨;如果输出小于0.5,则网络将其分类为不会下雨。即概率得分值越大,下雨的机会越大。
训练网络时,如果标签是下雨,则输入网络的目标值应为1,否则为0。
重要的一点是,如果你使用BCE损失函数,则节点的输出应介于(0-1)之间。这意味着你必须在最终输出中使用sigmoid激活函数。因为sigmoid函数可以把任何实数值转换(0–1)的范围。(也就是输出概率值)
如果你不想在最后一层上显示使用sigmoid激活函数,你可以在损失函数的参数上设置from logits为true,它会在内部调用Sigmoid函数应用到输出值。
多分类交叉熵
当你执行多类分类任务时,可以选择该损失函数。如果使用CCE(多分类交叉熵)损失函数,则输出节点的数量必须与这些类相同。最后一层的输出应该通过softmax激活函数,以便每个节点输出介于(0-1)之间的概率值。
例如,你有一个神经网络,它读取图像并将其分类为猫或狗。如果猫节点具有高概率得分,则将图像分类为猫,否则分类为狗。基本上,如果某个类别节点具有最高的概率得分,图像都将被分类为该类别。
为了在训练时提供目标值,你必须对它们进行一次one-hot编码。如果图像是猫,则目标向量将为(1,0),如果图像是狗,则目标向量将为(0,1)。基本上,目标向量的大小将与类的数目相同,并且对应于实际类的索引位置将为1,所有其他的位置都为零。
如果你不想在最后一层上显示使用softmax激活函数,你可以在损失函数的参数上设置from logits为true,它会在内部调用softmax函数应用到输出值。与上述情况相同。
稀疏多分类交叉熵
该损失函数几乎与多分类交叉熵相同,只是有一点小更改。
使用SCCE(稀疏多分类交叉熵)损失函数时,不需要one-hot形式的目标向量。例如如果目标图像是猫,则只需传递0,否则传递1。基本上,无论哪个类,你都只需传递该类的索引。
这些是最重要的损失函数。训练神经网络时,可能会使用这些损失函数之一。
下面的链接是Keras中所有可用损失函数的源代码。
()
BP原理(前馈神经网络)
公式中的e叫自然常数,也叫欧拉数,e=2.71828…。e是个很神秘的数字,它是“自然律”的精髓,其中暗藏着自然增长的奥秘,它的图形表达是旋涡形的螺线。
e = 1 + 1/1! + 1/2! + 1/3! + 1/4! + 1/5! + 1/6! + 1/7! + … = 1 + 1 + 1/2 + 1/6 + 1/24 + 1/120+ … ≈ 2.71828
bp基本原理是:
利用前向传播最后输出的结果来计算误差的偏导数,再用这个偏导数和前面的隐藏层进行加权求和,如此一层一层的向后传下去,直到输入层(不计算输入层),最后利用每个节点求出的偏导数来更新权重。
注意:隐藏层和输出层的值,都需要前一层加权求和之后 再代入激活函数 获得。
残差(error term) : 表示误差的偏导数
(注意:激活函数的导数中代入的值是前一层的加权值)
如果输出层用Purelin作激活函数,Purelin的导数是1,输出层→隐藏层:残差 = -(输出值-样本值)
如果用Sigmoid(logsig)作激活函数,那么: Sigmoid导数 = Sigmoid*(1-Sigmoid)
(Sigmoid指的是Sigmoid函数代入前一层的加权值得到的值,即输出值)
输出层→隐藏层:
残差 = -(输出值-样本值) * Sigmoid*(1-Sigmoid) = -(输出值-样本值)输出值(1-输出值)
隐藏层→隐藏层:
残差 = (右层每个节点的残差加权求和)* 当前节点的Sigmoid*(1-当前节点的Sigmoid)
如果用tansig作激活函数,那么:tansig导数 = 1 - tansig^2
残差全部计算好后,就可以更新权重了:
学习率是一个预先设置好的参数,用于控制每次更新的幅度。
此后,对全部数据都反复进行这样的计算,直到输出的误差达到一个很小的值为止。
这里介绍的是计算完一条记录,就马上更新权重,以后每计算完一条都即时更新权重。实际上批量更新的效果会更好,方法是在不更新权重的情况下,把记录集的每条记录都算过一遍,把要更新的增值全部累加起来求平均值,然后利用这个平均值来更新一次权重,然后利用更新后的权重进行下一轮的计算,这种方法叫批量梯度下降(Batch Gradient Descent)。

本文由作者笔名:丿聚焦丶灬 于 2023-03-29 18:44:01发表在本站,原创文章,禁止转载,文章内容仅供娱乐参考,不能盲信。
本文链接:https://www.e-8.com.cn/ly-129603.html
随机推荐

全职高手第一季樱花动漫(全职高手第一季樱花动漫二)
2023-03-29
石家庄亲子游玩好去处(石家庄亲子一日游最佳景点)
2023-08-13
貂蝉去掉所有服装没有小内(貂蝉去掉小内无爱心图)
2023-01-12
mj相机包值得买吗(1955相机包值得买吗)
2024-05-19
《活佛济公3》插曲-《佛前之愿》歌词(活佛济公歌曲胭脂泪)
2022-12-23
《狙击手 (2022)》免费在线观看完整版高清,求百度网盘资源(狙击手25集在线播放)
2023-01-15
春节放鞭炮风俗作文(春节放鞭炮作文400字作文)
2023-03-10
五行婚姻小说男主名字
2023-05-31
热门文章

《冷山》的“温暖”,妮可·基德曼演绎忠贞的爱情坚守,结局怎样(冷山帐篷区别)
2022-12-20
联想thinkpad10handheld(联想Thinkpad14寸笔记本)
2024-04-17
约达贾拉尔印度剧大结局(约尔达什)
2023-06-08
广东菜家常菜谱大全(广东菜谱家常菜做法)
2024-02-08
描写春天的优美片段200字左右(冬天的优美片段200字)
2023-01-16
中兴u950(中兴u950刷机包44)
2024-03-29
康辉老婆刘雅洁从事什么职业(康辉媳妇刘亚杰)
2023-06-09
大话西游2官网口袋版藏宝阁(大话西游端游口袋版宝阁)
2024-04-30