包含softmax的词条
 刻骨抵温柔。
刻骨抵温柔。- 旅游
- 2023-03-10 13:45:02
- -
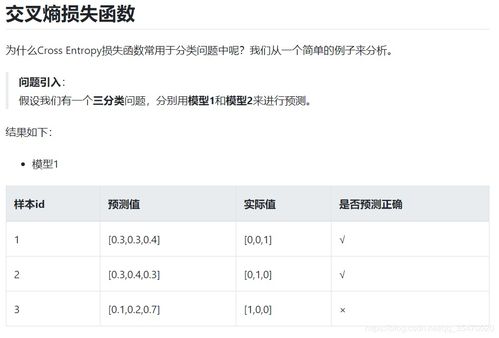
彻底理解 softmax、sigmoid、交叉熵(cross-entropy)
sigmoid 函数也叫S函数,因为它的函数曲线的形状像字母 S,由此得名。其形式为:
sigmoid 函数的输入是一个标量,输出也是一个标量,是一个标量到标量的映射。从函数曲线或函数表达式可以看出,sigmoid 函数的定义域为全体实数 ,值域为 (0,1) 区间,由此可以发现,sigmoid 函数能够起到将任意数值放缩到 (0,1) 区间内部。sigmoid 函数过去经常作为神经网络的激活函数,这是因为一方面 sigmoid 函数能够将那些过大或过小的数值缩放到 (0,1) 区间内部,同时还可以保持其相对大小;另一方面 sigmoid 函数的导数 ,可以发现 sigmoid 函数的导数可以由 sigmoid 本身直接得到,这个特性使得 sigmoid 函数在神经网络的反向传播过程中的求导十分容易。然而现在更常用的激活函数是形式更为简单的 ReLU 函数 。
值得一提的是,sigmoid 函数的原函数叫做 softplus 函数,其形式为:
softplus 函数的值域为 ,可用来产生正态分布的均值 和标准差 ,softplus 函数的名字来源于 函数的平滑形式。
softplus 函数的导数是 sigmoid 函数 。
softmax 函数,顾名思义是一种 max 函数,max 函数的作用是从一组数据中取最大值作为结果,而 softmax 也起到类似的作用,只是将这组数据进行一些处理,使得计算结果放缩到 (0,1) 区间内。
softmax 函数首先将这组数据中的每一个值 都转换为自然对数 的指数,即 ,随后将每个转换后的数据 都除以所有转换后数据的和 ,即 ,就是 softmax 对数据 的输出结果。这里需要注意的是,softmax 的作用是将一组数据的每一个都转换到 (0,1) 区间内,输入是一个向量,输出也是一个向量,是一个从向量到向量的映射;而 max 函数是将一组数据中的最大值作为输出,输入是一个向量,输出则是一个标量(一个数),是一个从向量到标量的映射,max 函数将输入数据的维度进行了压缩。
softmax 函数可视作 sigmoid 函数在向量上的扩展形式。sigmoid 函数的输入为一个标量,作用是将其放缩到 (0,1) 区间内,而 softmax 的输入为一个向量,输出也是一个向量,作用与 sigmoid 相同,只是 softmax 函数会保持这个向量内每个分量互相之间的相对大小(分量小的在 softmax 后依然小,分量大的在 softmax 后依然大)。考虑一个 2 维向量 , , ,当 时, ,其形式与 sigmoid 函数一致。
交叉熵 函数是用于计算两个概率分布之间的差异,其输入为两个分布,输出为一个标量,该标量表示两个分布之间的差异程度。交叉熵的形式为:
这里需要注意的是,在交叉熵函数中,交换分布 p 和 q 的顺序会影响交叉熵函数的输出结果,因为交叉熵函数 的作用是以分布 p 为基准,对分布 q 进行评估,将其交换顺序会导致评估的基准不一致, 与 的意义并不相同。
在深度学习中,经常将交叉熵函数与 softmax 函数相关联,这是因为 softmax 函数对一组数据的每个数据进行计算后,可以将这组数据中的每一个都映射到 (0,1) 区间上,并且其和为 1,符合概率的定义,而交叉熵恰恰是对概率分布进行计算,因此通常将 softmax 函数的输出结果作为交叉熵函数的输入,将二者构造为复合函数。
在深度学习的训练过程中,通常将每个输入的真实标签值设置为分布 p,预测值设置为分布 q,利用交叉熵函数计算出的值作为损失值,将其用于后续的反向传播计算梯度并更新权重。在这里,设 softmax 函数对输入数据 预测为第 类的概率为 ,输入数据 属于第 类的真实概率为 ,那么交叉熵函数的形式为:
根据以上公式,对模型预测的第 类的导数为:
softmax 函数对输入的导数的形式可由 softmax 本身得到,其形式十分简单(由于自然对数 的存在):
将 softmax 函数的输出作为交叉熵函数中的概率 ,即 ,那么交叉熵函数对 softmax 函数的输入 的导数为:
由于这里将 softmax 函数视作 p,即:
将 softmax 用 p 代替,也就是将 替换为 :
最后将上式代入到交叉熵函数的导数 中,即可得到交叉熵函数对输入 的导数:
可以看到交叉熵函数与 softmax 函数结合使用,可以得到十分简洁的导数形式,只需将 softmax 的输出结果减 1 再与对应的标签值 相乘即可得到在第 类上的导数,对每个类别分别计算相应的导数,即可得到我们需要的梯度。在许多任务中,标签值往往用 one-hot 形式表示, 一般为 1,那么只需将 softmax 函数的计算结果减 1 即可得到本次传播的第 类的导数值,这使得反向传播中梯度的计算变得十分简单和方便。
softmax修约公式
softmax修约公式,softmax可以将经交叉熵损失函数的输出都映射到 0 到 1 间,且各分类累和为 1。符合概率分布。
假设共有 n 个输出 [Z1,...,Zn],对第 i 个元素 Zi 的softmax的计算公式:Si = ezi / sum(ezn)

softmax原理及推导
本次记录内容主要为softmax的推导,部分内容有参考各网友文章
多分类问题符合多项式分布,softmax是一种用于解决多分类问题的有效方法。
softmax的推导思路为:
首先证明 多项分布属于指数分布族 ,这样就可以使用广义线性模型来拟合这个多项分布,由广义线性模型推导出的目标函数 h(x) 即为Softmax回归的分类模型。
(什么是指数分布族可参考我的另一篇 指数分布族函数与广义线性模型 )
多分类模型的输出是该样本属于k个类别的概率,从这k个概率中我们选择最优的概率对应的类别,作为该样本的预测类别。
这k个概率用k个变量 Θ1…Θk 来表示,这k个变量的和为1,即满足:
在这里,统计分量T(y)并没有像之前那样定义为T(y)=y,因为T(y)不是一个数值,而是一个k-1维的向量。下面使用 表示向量T(y)的第 i 个元素。
下面引入一个新的符号:
也就是说,向量T(y)的第 i 个元素是否为1是由当前y是否与 i 相等决定的。
T(y)是一个类似于onehot向量的东西,表示属于k类中的哪一个,则相应位置 i 会置为1。
那么可以得到:
多项式分布转化为指数分布族表达式过程如下:
上面转换过程中每一步的转换依据如下:
以上推导证明了:多项分布表达式可以表示为指数分布族表达式的格式,所以它属于指数分布族,那么就可以用广义线性模型来拟合这个多项式分布模型。
由η表达式可得:
[img]
本文由作者笔名:刻骨抵温柔。 于 2023-03-10 13:45:02发表在本站,原创文章,禁止转载,文章内容仅供娱乐参考,不能盲信。
本文链接:https://www.e-8.com.cn/ly-113541.html
相关文章
随机推荐

以春节为主题作文500字(以春节为话题的作文500字作文)
2023-11-22
张嘉译最火的四部电视剧,猎场上榜,你最喜欢哪部(张嘉译最新电视剧2022)
2023-01-24
佳能相机怎么调快门速度怎样解决佳能相机busy卡住了(佳能相机快门变慢)
2023-03-12
求 狙击手:特别行动 百度云免费在线观看资源(特别行动电视剧40集)
2023-01-27
nba历届选秀最强球员(nba历届选秀榜眼)
2023-05-10
黑店狂想曲高清完整版下载(邵氏电影在线观看)
2022-12-29
女人一定要去的旅游的地方(女人必须去的十个旅游景点)
2023-03-11
刘德华踢馆中国好声音是哪一期(明星踢馆好声音哪一期)
2023-01-19
热门文章

华为平板m6值得买吗(华为平板m6怎么样)
2023-01-11
韩庚为什么娶卢靖姗(韩庚卢靖姗新结婚了吗)
2023-01-10
富孩子穷孩子共多少集(穷孩子富孩子全集播放33集)
2023-02-28
fakervs岳伦岳伦和faker打的是什么比赛(faker和岳伦是哪一场比赛)
2023-06-11
生死路上分集剧情介绍(生死钟声分集剧情简介)
2023-01-16
吴宗宪一共有几个老婆和儿女。(吴宗宪几个孩子)
2023-01-22
目前最火的角色扮演手游()
2022-12-25
30个好词好句。(30个好词)
2023-01-04